World-R1 aligns text-to-video generation with 3D constraints through reinforcement learning, improving
geometric consistency while preserving visual quality and motion diversity.
We propose Chain-of-View (CoV) prompting, a training-free test-time reasoning framework that transforms
VLMs into active viewpoint reasoners for spatial reasoning in 3D environments.
We present DriveGen3D, a novel framework for generating high-quality and highly controllable dynamic 3D driving scenes that addresses critical limitations in existing methodologies.
We introduce PM-Loss, a novel regularization loss based on a learned point map for feed-forward 3DGS,
leading to smoother 3D geometry and better rendering.
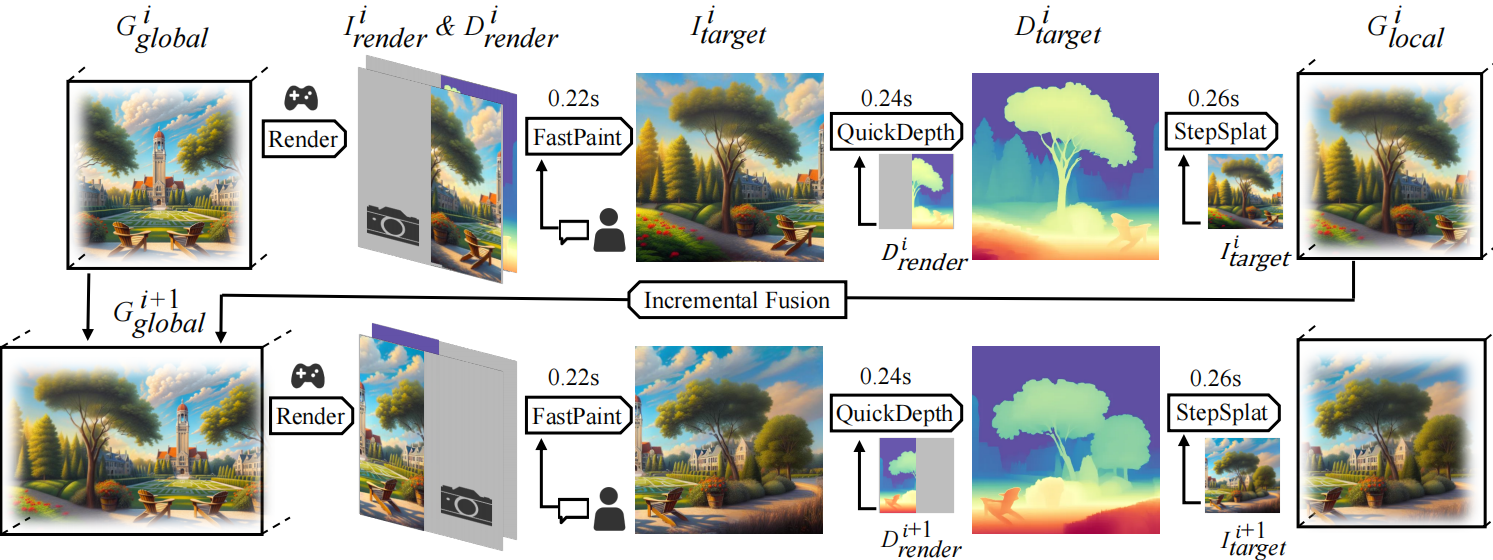
We introduce WonderTurbo, the first real-time interactive 3D scene generation framework capable of
generating novel perspectives of 3D scenes within 0.72 seconds.
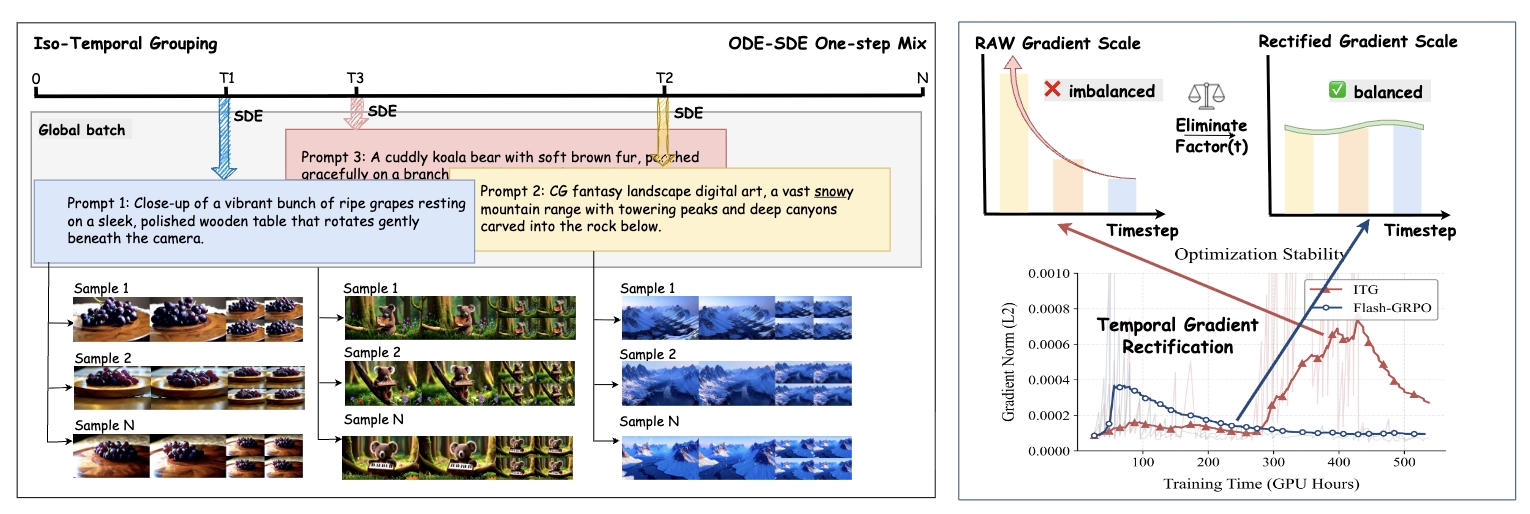
We introduce Flash-GRPO, a one-step policy optimization framework that improves video diffusion alignment
efficiency with iso-temporal grouping and temporal gradient rectification.
We introduce DiGSeg, a diffusion-based generalist segmentation framework that repurposes pretrained
diffusion models for text-conditioned semantic and open-vocabulary segmentation.
We introduce MV-RoboBench, a benchmark for evaluating multi-view spatial reasoning in robotic manipulation,
revealing large gaps between state-of-the-art VLMs and human performance.
We propose a single-view RGB-D-based depth completion framework, TransDiff, that leverages the Denoising
Diffusion Probabilistic Models(DDPM) to achieve material-agnostic object grasping in desktop.
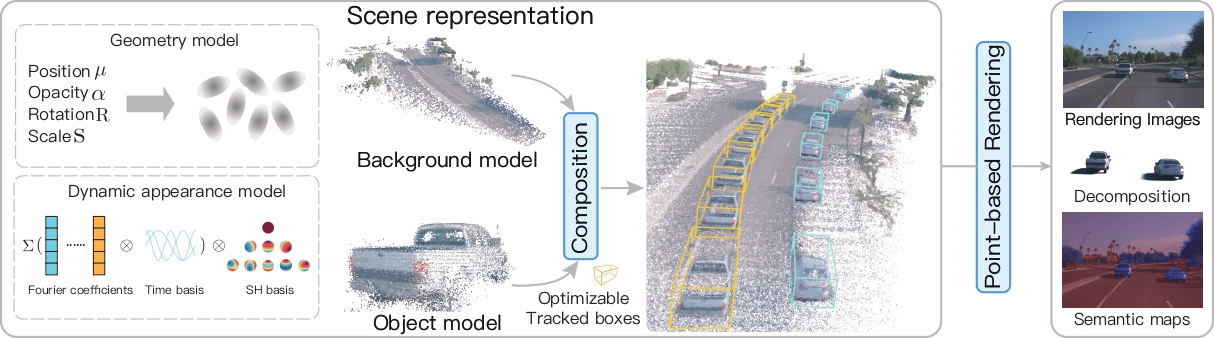
This paper aims to tackle the problem of modeling dynamic urban street scenes from monocular videos. We
introduce Street Gaussians, a new explicit scene representation that tackles some major limitations.
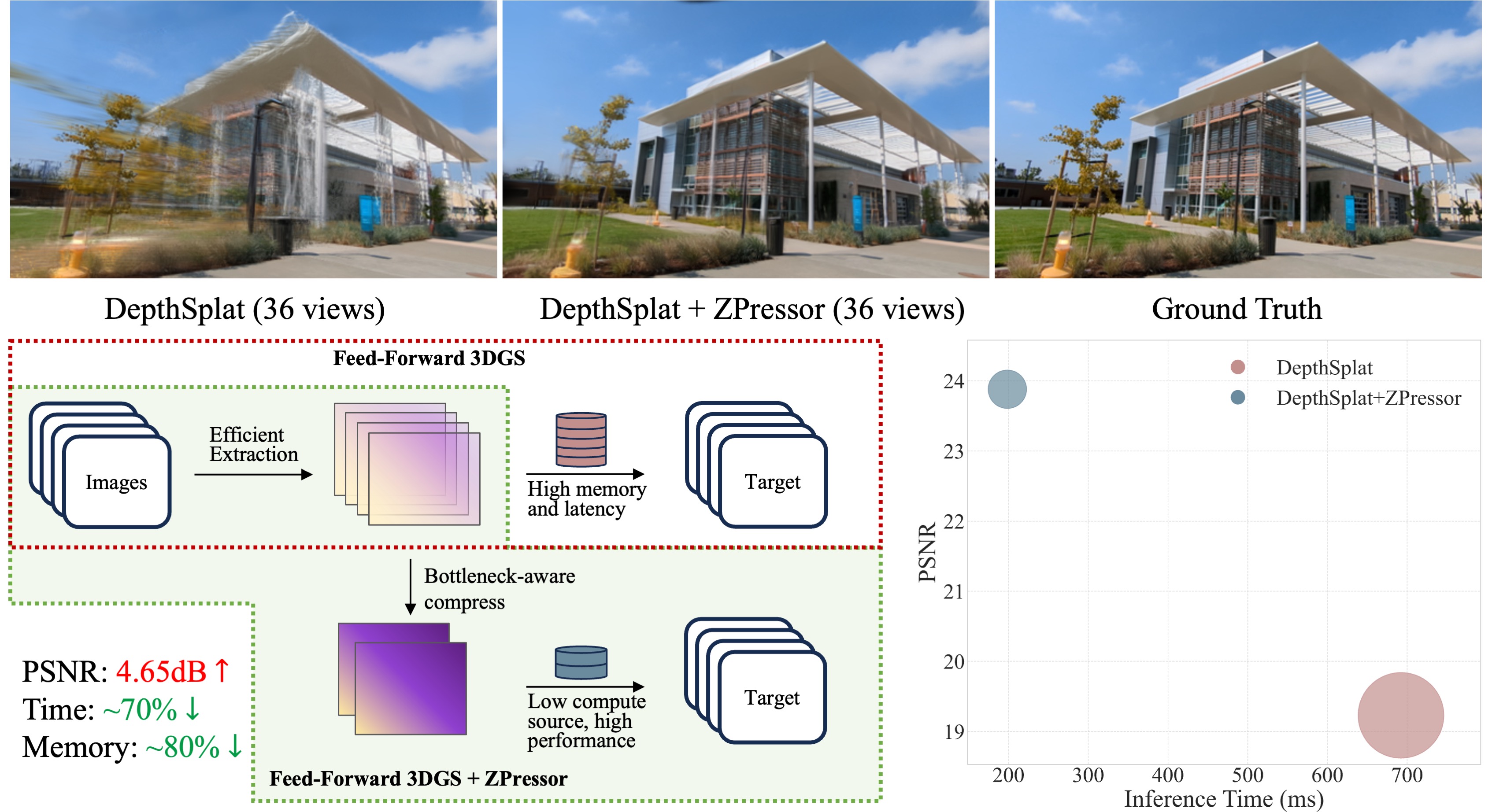
[2025/11/07] Invited talk of ZPressor: Bottleneck-Aware Compression for Scalable Feed-Forward
3DGS by EasyConferee at AI Alumni Center of Caohejing Hi-Tech Park.
[Slides]
[2025/06/16] Invited talk of ZPressor: Bottleneck-Aware Compression for Scalable Feed-Forward
3DGS by 3DCVer.
[Slides / Video]
Academic Service
Journal Reviewer: IEEE Transactions on Visualization and Computer Graphics (TVCG), The Visual Computer (TVC), IEEE Robotics and Automation Letters (RA-L)
Conference Reviewer: NeurIPS 2025, 3DV 2026, ICRA 2026, ICME 2026, ICML 2026, ECCV 2026, SIGGRAPH Asia 2026
Teaching Assistant
[Spring 2025] Database System, with Prof. Xiaoye Miao